The Linear Regression !!!
It is the most basic and widely used technique to predict a value of an attribute

What is Linear Regression?
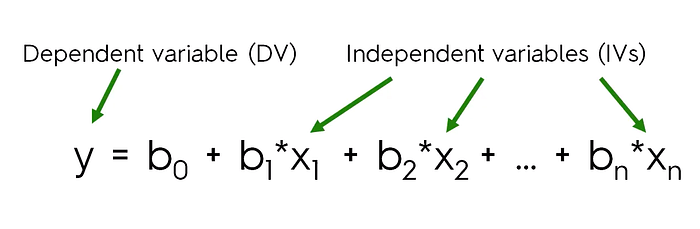
- Linear Regression is a supervised learning algorithm that depicts a relationship between the dependent variable(Y) and one or more independent variables(X)
- It is used to analyze continuous numeric data. It is used to predict quantitative variables by establishing a relationship between X and Y.
There are some assumptions that may become useful when we analyze our model to check whether it is accurate or not
- Independent variables should be linearly related to the dependent variable.
We can determine these by many visualization techniques like scatter plot, Heatmap. - Every feature(Attributes) in the data is Normally Distributed.
this can also be checked by the histogram(Visualization) - There should be little or no multi-collinearity in the data.
The best way to check the presence of multi-collinearity is to perform VIF(Variance Inflation Factor). - The mean of the residual is zero.
The residual value is the distance between the data point and line. If this difference comes nearer to zero that means our model is working properly and accurately.
→ If the observed points are far from the regression line, then the residual will be high, and so the cost function will high. - No autocorrelations:
If there will be any correlation in the error term, then it will dramatically reduce the accuracy of the model. Autocorrelation usually occurs if there is a dependency between residual errors. - Homoscedasticity Assumption (Same Variance):
The assumption of equal variances (i.e. assumption of homoscedasticity) assumes that different samples have the same variance, even if they came from different populations. The assumption is found in many statistical tests, including Analysis of Variance (ANOVA) and Student’s T-Test.


Where,
ȳ = mean of y-values
ŷi = i-th predicted value
yi =i-th y-value
u = yi — ŷi =residual
Types of Linear Regression :
- Simple Linear Regression:-
This type of regression helps to find a linear relationship between only two variables where one is dependent(Y) and the other is an independent variable(X).
→ The formula of Simple Linear Regression like Stright line formula y=mx+c.
→Our main goal is to find the value of ‘m’ and ‘c’ in such a way that it gives us the smallest sum of squared(SSE)
→The formula of Simple Linear Regression:

2. Multiple Linear Regression:-
This type of linear regression is the most commonly used technique in predictive analysis. It is used to explain the relationship between one dependent(Y) and two or more independent variables.
→For multiple linear regression we can write:
Y=mx1+mx2+mx3+…..+mxn+c
There are 3 main metrics for model evaluation in regression:
- R Square/Adjusted R Square
→ R-squared is a statistical method that determines the goodness of fit.
→ It measures the strength of the relationship between the dependent and independent variables on a scale of 0–100% or 0–1.
→ The high value of R-square represents there is less difference between the predicted value and the actual value means the model is good.
→ R-Squared, also known as the Coefficient of Determination
→If we get 60% or 0.6 we can say that there is a 60 % reduction in variation when we take a particular independent variable in the calculation.
→ or 60% of the sum of squared of the independent variable explain by that independent variable.
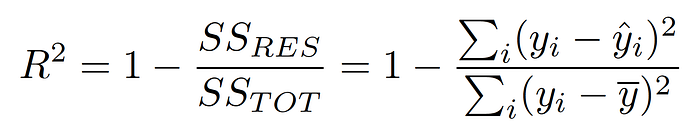
Here SSTOT=SSR(Sum of Squared residuals)
2. Mean Square Error(MSE)
→The mean squared error tells you how close a regression line is to a set of points.
→This can be calculated by taking distances(yi - ŷi) from the regression line for each and every point and squaring them.
→Mean Square Error is an absolute measure of the goodness for the fit.
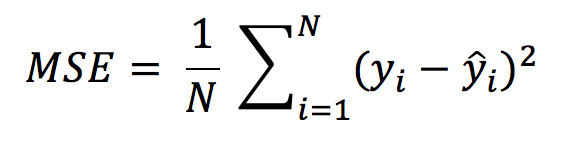
3. Mean Absolute Error(MAE)
→ Mean Absolute Error(MAE) is similar to Mean Square Error(MSE).
→ However, instead of the sum of the square of error in MSE, MAE is taking the sum of the absolute value of error.
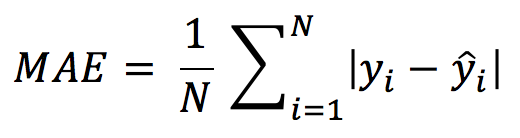
Performance Of Multiple Linear Regression:
link: http://www.ijastnet.com/journals/Vol_1_No4_July_2011/5.pdf

Cost Function:
→ The cost function is a function that measures the performance of ML models for given data.
→ It finds an error between the predicted value and the actual value and shows in form of a single number/value.
→ Cost Function is the average error of n-sample in the data.
1. Mean Absolute Error
2. Mean Squared Error
3. Root Mean Squared Error
4. Root Mean Squared Logarithmic Error.
Loss Function:
→Loss Function is the error for individual data points.
→Mean Squared Error(MSE) & Mean Absolute Error(MAE)
CODE : https://github.com/prakharninja0927/Machine-Learning/tree/main/Regression
Thanks for Reading
If you like my work and want to support me…
